Centralized Critic: Multi-Observation Variance
This blog gives a toy example called Guess Game, explaining Multi-Observation Variance in our work on Centralized Critic.
The following figure shows the environment Guess Game.
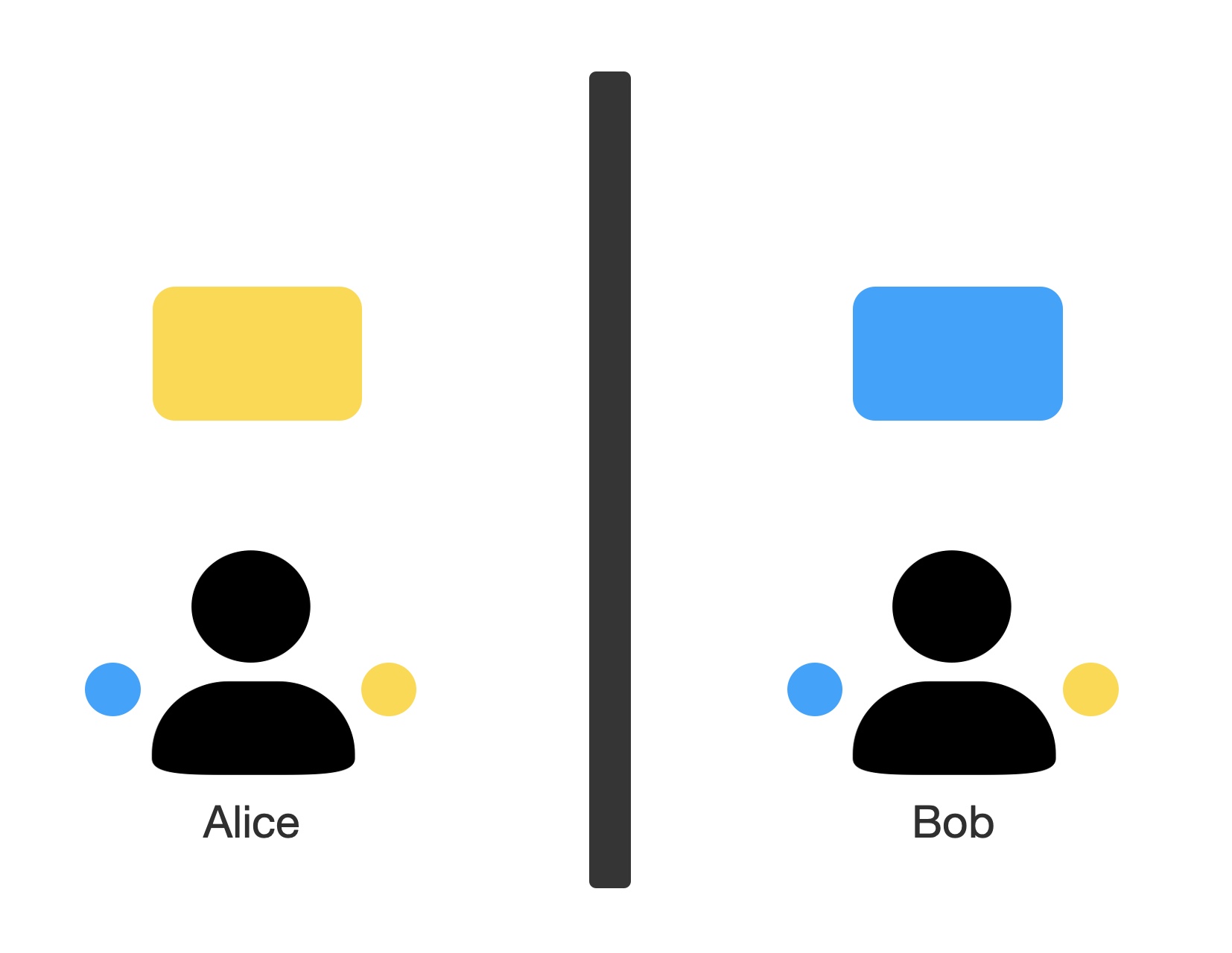
Alice and Bob are placed in two different rooms, and each observe a uniformly initialized blue-or-yellow colored screen, and they have two buttons they can press. They are rewarded +1 by pressing the button with color that matches the other person’s observation.
It’s obvious that their chance of getting the reward is 0.5, cause they can’t observe the other person’s observation.
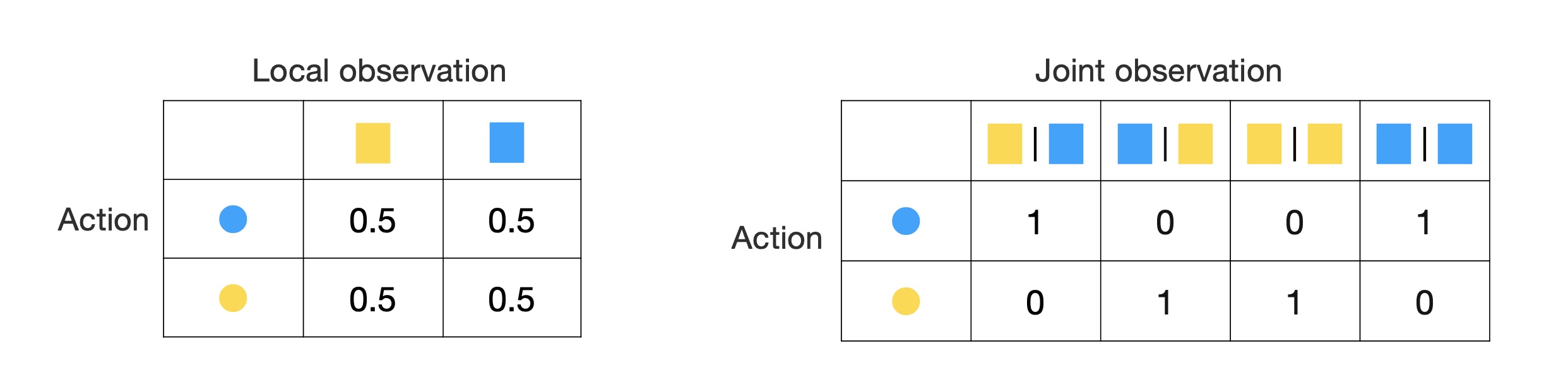
So decentralized citric (on the left) will tell us that our expected return is 0.5. The centralized critic, on the right hand side, gives us 1s and 0s each half of the time, as it also conditions on the other agent’s observation, Of course, this is correct; but for any given action, 0.5 have no variance while 1s and 0s have positive variance. As a result, we get more variance from centralized critic.
Guess game is an extreme example, in that you gather zero information about the other agent’s observations based on your own observations. And that’s when you have the highest multi-observation variance. But it highlights the fact that when we talk about local value for a certain history, we are implicitly or explicitly marginalizing over the joint history space. And that is the source of multi-observation variance.
Xueguang Lyu
CS Ph.D. Candidate
My research interests include reinforcement learning and multi-agent cooperation.